Что такое Хэш?
 В рамках данной статьи, я расскажу вам что такое Хэш, зачем он нужен, где и как применяется, а так же наиболее известные примеры.
В рамках данной статьи, я расскажу вам что такое Хэш, зачем он нужен, где и как применяется, а так же наиболее известные примеры.
Многие задачи в области информационных технологий весьма критичны к объемам данных. Например, если нужно сравнить между собой два файла размером по 1 Кб и два файла по 10 Гб, то это совершенно разное время. Поэтому алгоритмы, позволяющие оперировать более короткими и емкими значениями, считаются весьма востребованными.
Одной из таких технологий является Хэширование, которое нашло свое применение при решении массы задач. Но, думаю вам, как обычному пользователю, все еще непонятно, что же это за зверь такой и для чего он нужен. Поэтому далее я постараюсь объяснить все наиболее простыми словами.
Примечание: Материал рассчитан на обычных пользователей и не содержит многих технических аспектов, однако для базового ознакомления его более, чем достаточно.
Что такое Хэш или Хэширование?
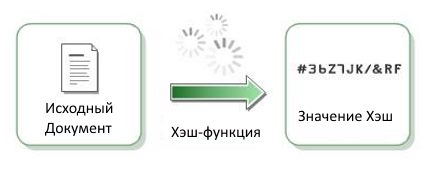
Начну с терминов.
Хэш-функция, Функция свертки — это специального вида функция, которая позволяет преобразовывать произвольной длины тексты к коду фиксированной длины (обычно, короткая цифро-буквенная запись).
Хэширование — это сам процесс преобразования исходных текстов.
Хэш, Хеш-код, Значение Хэш, Хэш-сумма — это выходное значение Хэш-функции, то есть полученный блок фиксированный длины.
Как видите, у терминов несколько образное описание, из которого сложно понять для чего это все нужно. Поэтому сразу приведу небольшой пример (об остальных применениях расскажу чуть позже). Допустим, у вас есть 2 файла размером 10 Гб. Как можно быстро узнать какой из них нужный? Можно использовать имя файла, но его легко переименовать. Можно смотреть даты, но после копирования файлов даты могут быть одинаковыми или в иной последовательности. Размер, как сами понимаете, мало чем может помочь (особенно, если размеры совпадают или вы не смотрели точные значения байтов).
Вот тут-то и нужен этот самый Хэш, который представляет собой короткий блок, формирующийся из исходного текста файла. У этих двух файлов по 10 Гб будет два разных, но коротких Хэш-кода (что-то вроде «ACCAC43535» и «BBB3232A42»). Используя их, можно будет быстро узнать нужный файл, даже после копирования и смены имен.
Примечание: В связи с тем, что Хэш в компьютером мире и в интернете весьма известное понятие, то нередко все то, что имеет отношение к Хэшу, сокращают до этого самого слова. Например, фраза «у меня используется Хэш MD5» в переводе означает, что на сайте или где-то еще используется алгоритм хэширования стандарта MD5.
Свойства Хеш-функций
Теперь, расскажу о свойствах Хэш-функций, чтобы вам было легче понять где применяется и для чего нужно Хэширование. Но, сначала еще одно определение.
Коллизия — это ситуация, когда для двух разных текстов получается одна и та же Хэш-сумма. Как сами понимаете, раз блок фиксированной длины, то он имеет ограниченное число возможных значений, а следовательно возможны повторы.
А теперь к самим свойствам Хэш-функций:
1. На вход может подаваться текст любого размера, а на выходе получается блок данных фиксированной длины. Это следует из определения.
2. Хэш-сумма одних и тех же текстов должна быть одинаковой. В противном случае, такие функции просто бесполезны — это аналогично случайному числу.
3. Хорошая функция свертки должна иметь хорошее распределение. Согласитесь, что если размер выходного Хэша, к примеру, 16 байт, то если функция возвращает всего 3 разных значения для любых текстов, то толку от такой функции и этих 16 байт никакого (16 байт это 2^128 вариантов, что примерно равно 3,4 * 10^38 степени).
4. Как хорошо функция реагирует на малейшие изменения в исходном тексте. Простой пример. Поменяли 1 букву в файле размером 10 Гб, значение функции должно стать другим. Если же это не так, то применять такую функцию весьма проблематично.
5. Вероятность возникновения коллизии. Весьма сложный параметр, рассчитываемый при определенных условиях. Но, суть его в том, что какой смысл от Хэш-функции, если полученная Хэш-сумма будет часто совпадать.
6. Скорость вычисления Хэша. Какой толк от функции свертки, если она будет долго вычисляться? Никакой, ведь тогда проще данные файлов сравнивать или использовать иной подход.
7. Сложность восстановления исходных данных из значения Хэша. Эта характеристика больше специфическая, нежели общая, так как не везде требуется подобное. Однако, для наиболее известных алгоритмов эта характеристика оценивается. Например, исходный файл вы вряд ли сможете получить из этой функции. Однако, если имеет место проблема коллизий (к примеру, нужно найти любой текст, который соответствует такому Хэшу), то такая характеристика может быть важной. Например, пароли, но о них чуть позже.
8. Открыт или закрыт исходный код такой функции. Если код не является открытым, то сложность восстановления данных, а именно криптостойкость, остается под вопросом. Отчасти, это проблема как с шифрованием.
Вот теперь можно переходить к вопросу «а для чего это все?».
Зачем нужен Хэш?
Основные цели у Хэш-функций всего три (вернее их предназначения).
1. Проверка целостности данных. В данном случае все просто, такая функция должна вычисляться быстро и позволять так же быстро проверить, что, к примеру, скачанный из интернета файл не был поврежден во время передачи.
2. Рост скорости поиска данных. Фиксированный размер блока позволяет получить немало преимуществ в решении задач поиска. В данном случае, речь идет о том, что, чисто технически, использование Хэш-функций может положительно сказываться на производительности. Для таких функций весьма важное значение представляют вероятность возникновения коллизий и хорошее распределение.
3. Для криптографических нужд. Данный вид функций свертки применяется в тех областях безопасности, где важно чтобы результаты сложно было подменить или где необходимо максимально усложнить задачу получения полезной информации из Хэша.
Где и как применяется Хэш?
Как вы, вероятно, уже догадались Хэш применяется при решении очень многих задач. Вот несколько из них:
1. Пароли обычно хранятся не в открытом виде, а в виде Хэш-сумм, что позволяет обеспечить более высокую степень безопасности. Ведь даже если злоумышленник получит доступ к такой БД, ему еще придется немало времени потратить, чтобы подобрать к этим Хэш-кодам соответствующие тексты. Вот тут и важна характеристика «сложность восстановления исходных данных из значений Хэша».
2. В программировании, включая базы данных. Конечно же, чаще всего речь идет о структурах данных, позволяющих осуществлять быстрый поиск. Чисто технический аспект.
3. При передачи данных по сети (включая Интернет). Многие протоколы, такие как TCP/IP, включают в себя специальные проверочные поля, содержащие Хэш-сумму исходного сообщения, чтобы если где-то произошел сбой, то это не повлияло на передачу данных.
4. Для различных алгоритмов, связанных с безопасностью. Например, Хэш применяется в электронных цифровых подписях.
5. Для проверки целостности файлов. Если обращали внимание, то нередко в интернете можно встретить у файлов (к примеру, архивы) дополнительные описания с Хэш-кодом. Эта мера применяется не только для того, чтобы вы случайно не запустили файл, который повредился при скачивании из Интернета, но и бывают просто сбои на хостингах. В таких случаях, можно быстро проверить Хэш и если требуется, то перезалить файл.
6. Иногда, Хэш-функции применяются для создания уникальных идентификаторов (как часть). Например, при сохранении картинок или просто файлов, обычно используют Хэш в именах совместно с датой и временем. Это позволяет не перезаписывать файлы с одинаковыми именами.
На самом деле, чем дальше, тем чаще Хэш-функции применяются в информационных технологиях. В основном из-за того, что объемы данных и мощности самых простых компьютеров сильно возрасли. В первом случае, речь больше о поиске, а во втором речь больше о вопросах безопасности.
Известные Хэш-функции
Самыми известными считаются следующие три Хэш-функции:
1. CRC16, CRC32, CRC64 — эти Хэш-функции очень просты и применяются только для проверки целостности данных. Например, при передачи данных по сети. При этом цифра после CRC — это не более, чем количество бит в выходном блоке. Самым известным из них является CRC32, размер Хэш-кода которого составляет всего 4 байта.
Примечание: Данная функция свертки состоит всего из одной операции XOR, которая последовательно выполняется ко всем входным блокам исходного текста. Поэтому ее обычно применяют только для проверки целостности данных.
2. MD5 — в свое время эта Хэш-функция была очень популярна для хранения паролей и прочих целей безопасности. Размер выходного блока составляет 128 бит. В принципе, применяется и до сих пор, однако стоит знать, что стойкость этого алгоритма уже не столько хороша (банально мощности компьютеров выросли — смотрите пример в статье, которую указал в предыдущем подразделе).
3. SHA-1, SHA-2 — самым известным и поддерживаемым многими системами является стандарт SHA-1 (160 бит). Однако, постепенно идет переход на SHA-2 (от 224 бит до 512), так как стойкость первого алгоритма постепенно снижается, как и у MD5.
На самом деле, в РФ существует и применяется собственный криптостойкий алгоритм ГОСТ Р 34.11-2012 (ранее использовался ГОСТ Р 34.11-94), однако распространенность его в интернете очень мала (в плане известности).
Теперь, вы знаете что такое Хэш, для чего он применяется и ряд других аспектов.
Хеш-функция, что это такое?

Сегодня я хотел бы рассказать о том, что из себя представляет хеш-функция, коснуться её основных свойств, привести примеры использования и в общих чертах разобрать современный алгоритм хеширования SHA-3, который был опубликован в качестве Федерального Стандарта Обработки Информации США в 2015 году.
Общие сведения
Криптографическая хеш-функция — это математический алгоритм, который отображает данные произвольного размера в битовый массив фиксированного размера.
Результат, производимый хеш-функцией, называется «хеш-суммой» или же просто «хешем», а входные данные часто называют «сообщением».
Для идеальной хеш-функции выполняются следующие условия:
а) хеш-функция является детерминированной, то есть одно и то же сообщение приводит к одному и тому же хеш-значению
b) значение хеш-функции быстро вычисляется для любого сообщения
c) невозможно найти сообщение, которое дает заданное хеш-значение
d) невозможно найти два разных сообщения с одинаковым хеш-значением
e) небольшое изменение в сообщении изменяет хеш настолько сильно, что новое и старое значения кажутся некоррелирующими
Давайте сразу рассмотрим пример воздействия хеш-функции SHA3-256.
Число 256 в названии алгоритма означает, что на выходе мы получим строку фиксированной длины 256 бит независимо от того, какие данные поступят на вход.
На рисунке ниже видно, что на выходе функции мы имеем 64 цифры шестнадцатеричной системы счисления. Переводя это в двоичную систему, получаем желанные 256 бит.
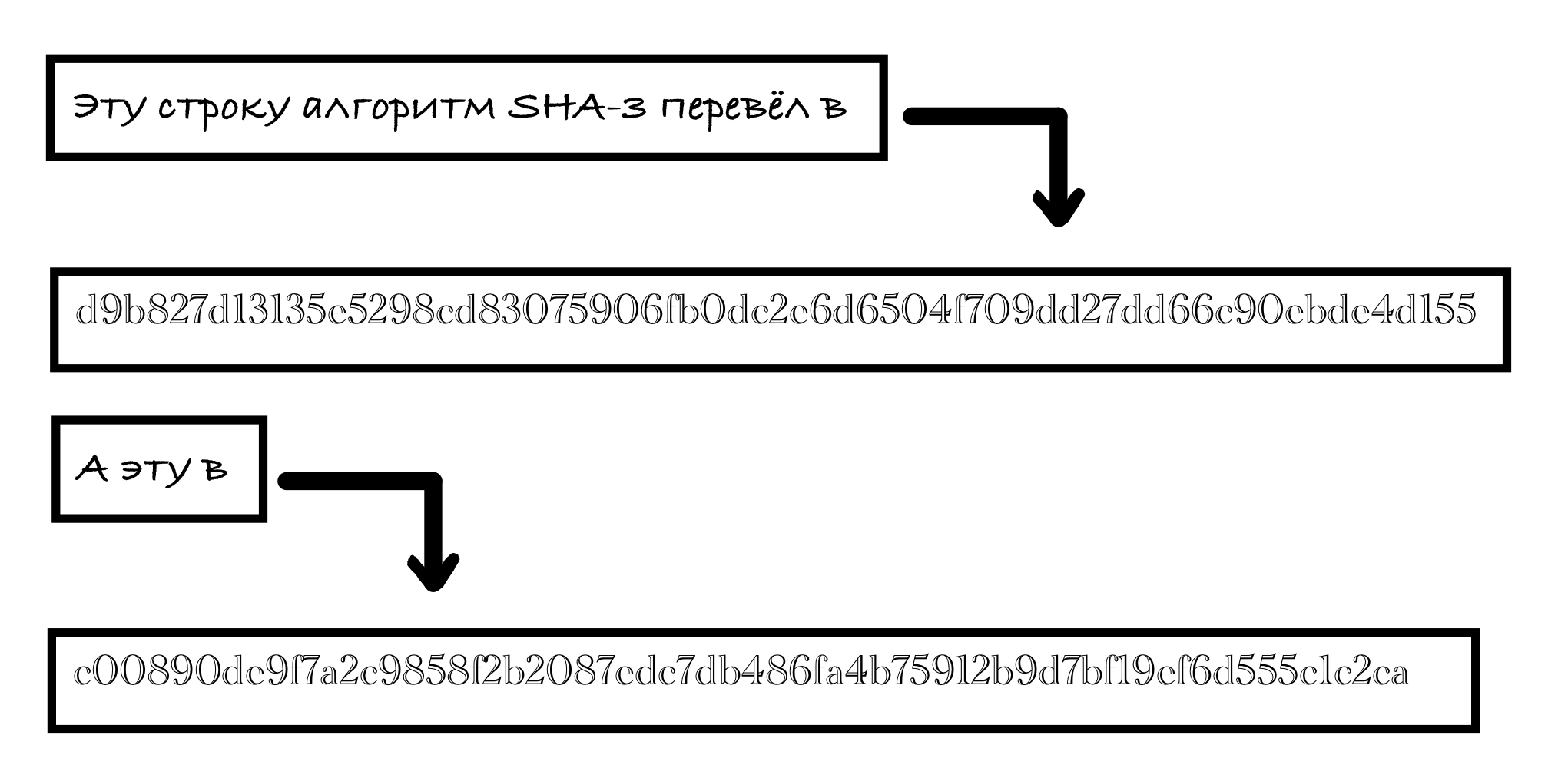
Любой заинтересованный читатель задаст себе вопрос: «А что будет, если на вход подать данные, бинарный код которых во много раз превосходит 256 бит?»
Ответ таков: на выходе получим все те же 256 бит!
Дело в том, что 256 бит — это соответствий, то есть различных входов имеют свой уникальный хеш.
Чтобы прикинуть, насколько велико это значение, запишем его следующим образом:
Надеюсь, теперь нет сомнений в том, что это очень внушительное число!
Поэтому ничего не мешает нам сопоставлять длинному входному массиву данных массив фиксированной длины.
Свойства
Криптографическая хеш-функция должна уметь противостоять всем известным типам криптоаналитических атак.
В теоретической криптографии уровень безопасности хеш-функции определяется с использованием следующих свойств:
Pre-image resistance
Имея заданное значение h, должно быть сложно найти любое сообщение m такое, что
Second pre-image resistance
Имея заданное входное значение , должно быть сложно найти другое входное значение такое, что
Collision resistance
Должно быть сложно найти два различных сообщения и таких, что
Такая пара сообщений и называется коллизией хеш-функции
Давайте чуть более подробно поговорим о каждом из перечисленных свойств.
Collision resistance. Как уже упоминалось ранее, коллизия происходит, когда разные входные данные производят одинаковый хеш. Таким образом, хеш-функция считается устойчивой к коллизиям до того момента, пока не будет обнаружена пара сообщений, дающая одинаковый выход. Стоит отметить, что коллизии всегда будут существовать для любой хеш-функции по той причине, что возможные входы бесконечны, а количество выходов конечно. Хеш-функция считается устойчивой к коллизиям, когда вероятность обнаружения коллизии настолько мала, что для этого потребуются миллионы лет вычислений.
Несмотря на то, что хеш-функций без коллизий не существует, некоторые из них достаточно надежны и считаются устойчивыми к коллизиям.
Pre-image resistance. Это свойство называют сопротивлением прообразу. Хеш-функция считается защищенной от нахождения прообраза, если существует очень низкая вероятность того, что злоумышленник найдет сообщение, которое сгенерировало заданный хеш. Это свойство является важным для защиты данных, поскольку хеш сообщения может доказать его подлинность без необходимости раскрытия информации. Далее будет приведён простой пример и вы поймете смысл предыдущего предложения.
Second pre-image resistance. Это свойство называют сопротивлением второму прообразу. Для упрощения можно сказать, что это свойство находится где-то посередине между двумя предыдущими. Атака по нахождению второго прообраза происходит, когда злоумышленник находит определенный вход, который генерирует тот же хеш, что и другой вход, который ему уже известен. Другими словами, злоумышленник, зная, что пытается найти такое, что
Отсюда становится ясно, что атака по нахождению второго прообраза включает в себя поиск коллизии. Поэтому любая хеш-функция, устойчивая к коллизиям, также устойчива к атакам по поиску второго прообраза.
Неформально все эти свойства означают, что злоумышленник не сможет заменить или изменить входные данные, не меняя их хеша.
Таким образом, если два сообщения имеют одинаковый хеш, то можно быть уверенным, что они одинаковые.
В частности, хеш-функция должна вести себя как можно более похоже на случайную функцию, оставаясь при этом детерминированной и эффективно вычислимой.

Применение хеш-функций
Рассмотрим несколько достаточно простых примеров применения хеш-функций:
• Проверка целостности сообщений и файлов
Сравнивая хеш-значения сообщений, вычисленные до и после передачи, можно определить, были ли внесены какие-либо изменения в сообщение или файл.
• Верификация пароля
Проверка пароля обычно использует криптографические хеши. Хранение всех паролей пользователей в виде открытого текста может привести к массовому нарушению безопасности, если файл паролей будет скомпрометирован. Одним из способов уменьшения этой опасности является хранение в базе данных не самих паролей, а их хешей. При выполнении хеширования исходные пароли не могут быть восстановлены из сохраненных хеш-значений, поэтому если вы забыли свой пароль вам предложат сбросить его и придумать новый.
• Цифровая подпись
Подписываемые документы имеют различный объем, поэтому зачастую в схемах ЭП подпись ставится не на сам документ, а на его хеш. Вычисление хеша позволяет выявить малейшие изменения в документе при проверке подписи. Хеширование не входит в состав алгоритма ЭП, поэтому в схеме может быть применена любая надежная хеш-функция.
Предлагаю также рассмотреть следующий бытовой пример:
Алиса ставит перед Бобом сложную математическую задачу и утверждает, что она ее решила. Боб хотел бы попробовать решить задачу сам, но все же хотел бы быть уверенным, что Алиса не блефует. Поэтому Алиса записывает свое решение, вычисляет его хеш и сообщает Бобу (сохраняя решение в секрете). Затем, когда Боб сам придумает решение, Алиса может доказать, что она получила решение раньше Боба. Для этого ей нужно попросить Боба хешировать его решение и проверить, соответствует ли оно хеш-значению, которое она предоставила ему раньше.
Теперь давайте поговорим о SHA-3.

Национальный институт стандартов и технологий (NIST) в течение 2007—2012 провёл конкурс на новую криптографическую хеш-функцию, предназначенную для замены SHA-1 и SHA-2.
Организаторами были опубликованы некоторые критерии, на которых основывался выбор финалистов:
Способность противостоять атакам злоумышленников
• Производительность и стоимость
Вычислительная эффективность алгоритма и требования к оперативной памяти для программных реализаций, а также количество элементов для аппаратных реализаций
• Гибкость и простота дизайна
Гибкость в эффективной работе на самых разных платформах, гибкость в использовании параллелизма или расширений ISA для достижения более высокой производительности
В финальный тур попали всего 5 алгоритмов:
Победителем и новым SHA-3 стал алгоритм Keccak.
Давайте рассмотрим Keccak более подробно.
Keccak
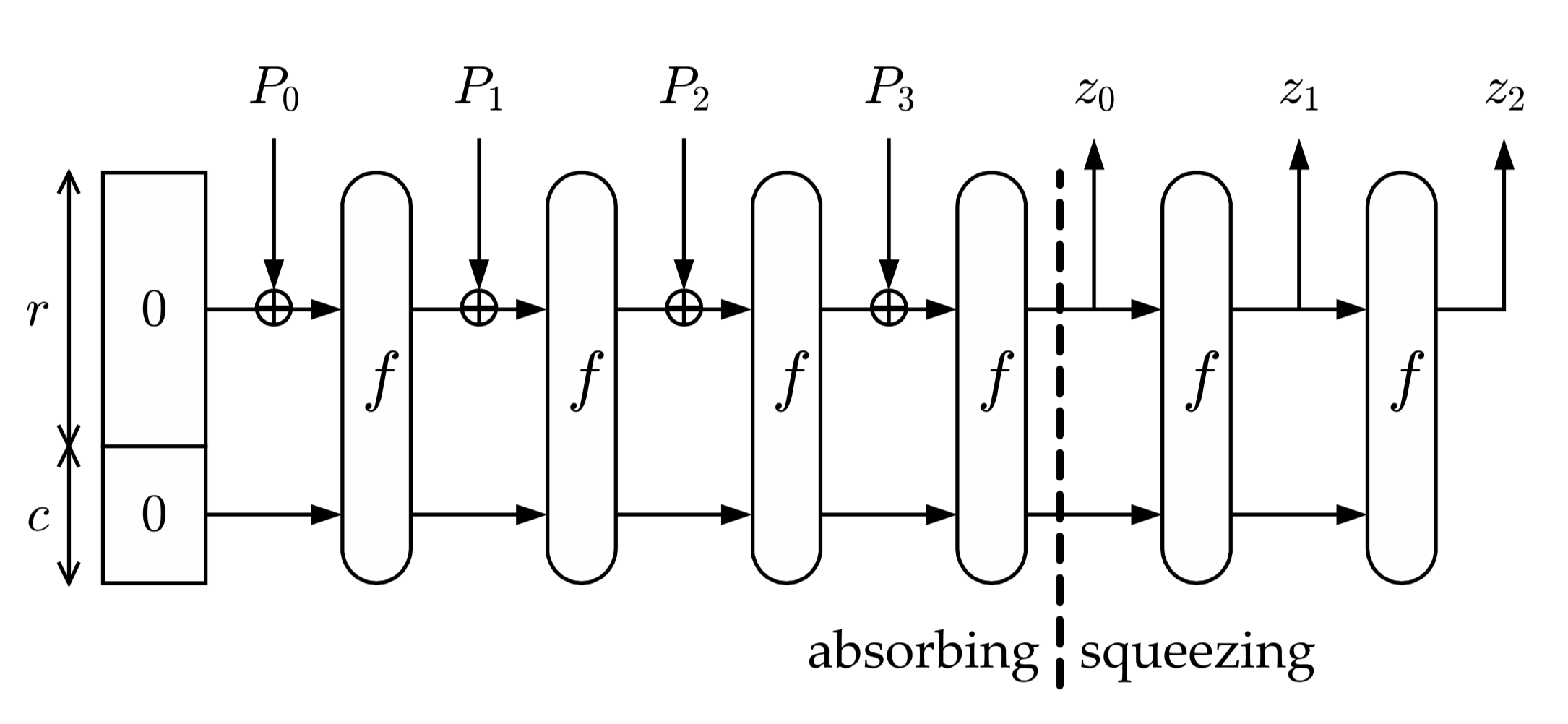
Хеш-функции семейства Keccak построены на основе конструкции криптографической губки, в которой данные сначала «впитываются» в губку, а затем результат Z «отжимается» из губки.
Любая губчатая функция Keccak использует одну из семи перестановок которая обозначается , где
перестановки представляют собой итерационные конструкции, состоящие из последовательности почти одинаковых раундов. Число раундов зависит от ширины перестановки и задаётся как где
В качестве стандарта SHA-3 была выбрана перестановка Keccak-f[1600], для неё количество раундов
Далее будем рассматривать
Давайте сразу введем понятие строки состояния, которая играет важную роль в алгоритме.
Строка состояния представляет собой строку длины 1600 бит, которая делится на и части, которые называются скоростью и ёмкостью состояния соотвественно.
Соотношение деления зависит от конкретного алгоритма семейства, например, для SHA3-256
В SHA-3 строка состояния S представлена в виде массива слов длины бит, всего бит. В Keccak также могут использоваться слова длины , равные меньшим степеням 2.
Алгоритм получения хеш-функции можно разделить на несколько этапов:
• С помощью функции дополнения исходное сообщение M дополняется до строки P длины кратной r
• Строка P делится на n блоков длины
• «Впитывание»: каждый блок дополняется нулями до строки длиной бит (b = r+c) и суммируется по модулю 2 со строкой состояния , далее результат суммирования подаётся в функцию перестановки и получается новая строка состояния , которая опять суммируется по модулю 2 с блоком и дальше опять подаётся в функцию перестановки . Перед началом работы криптографической губки все элементыравны 0.
• «Отжимание»: пока длина результата меньше чем , где — количество бит в выходном массиве хеш-функции, первых бит строки состояния добавляется к результату . После каждой такой операции к строке состояния применяется функция перестановок и данные продолжают «отжиматься» дальше, пока не будет достигнуто значение длины выходных данных .
Все сразу станет понятно, когда вы посмотрите на картинку ниже:
Функция дополнения
В SHA-3 используется следующий шаблон дополнения 10. 1: к сообщению добавляется 1, после него от 0 до r — 1 нулевых бит и в конце добавляется 1.
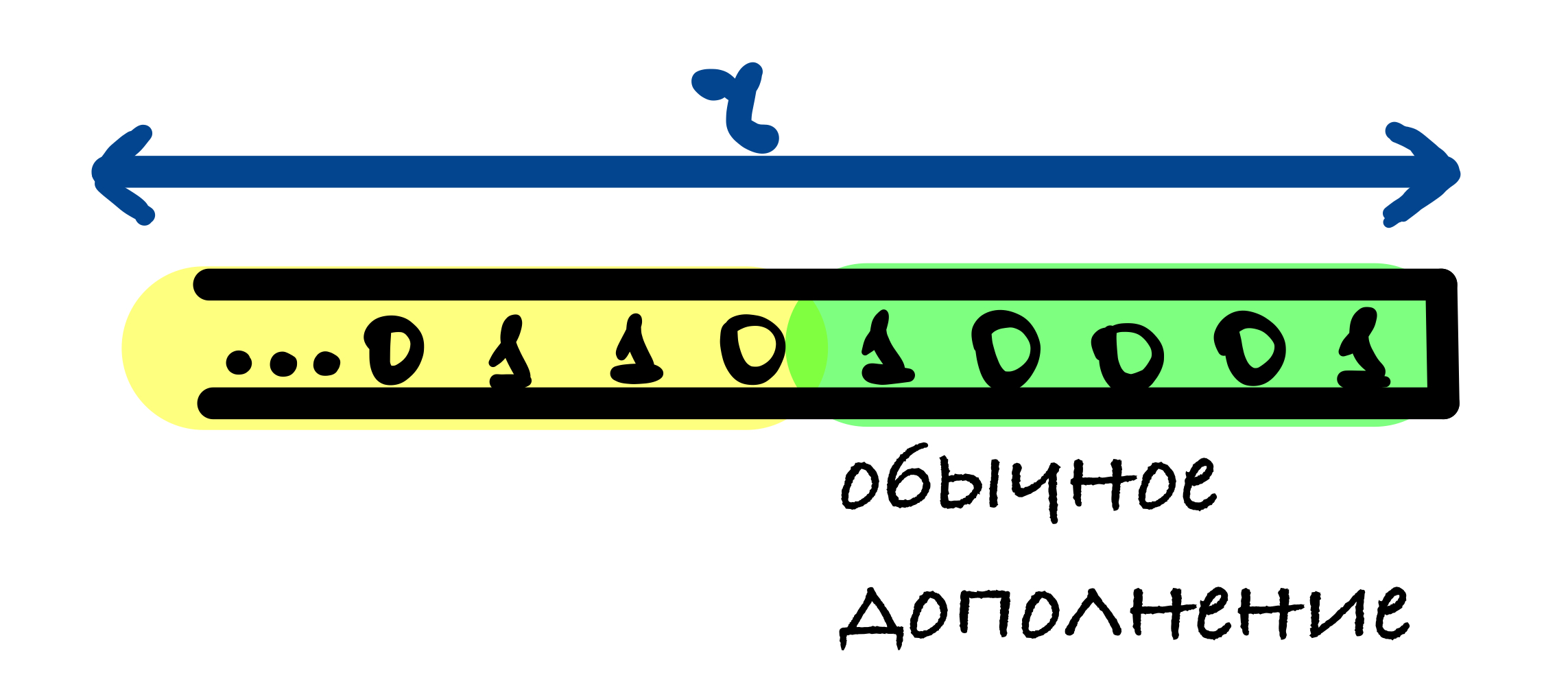
r — 1 нулевых бит может быть добавлено, когда последний блок сообщения имеет длину r — 1 бит. В этом случае последний блок дополняется единицей и к нему добавляется блок, состоящий из r — 1 нулевых бит и единицы в конце.
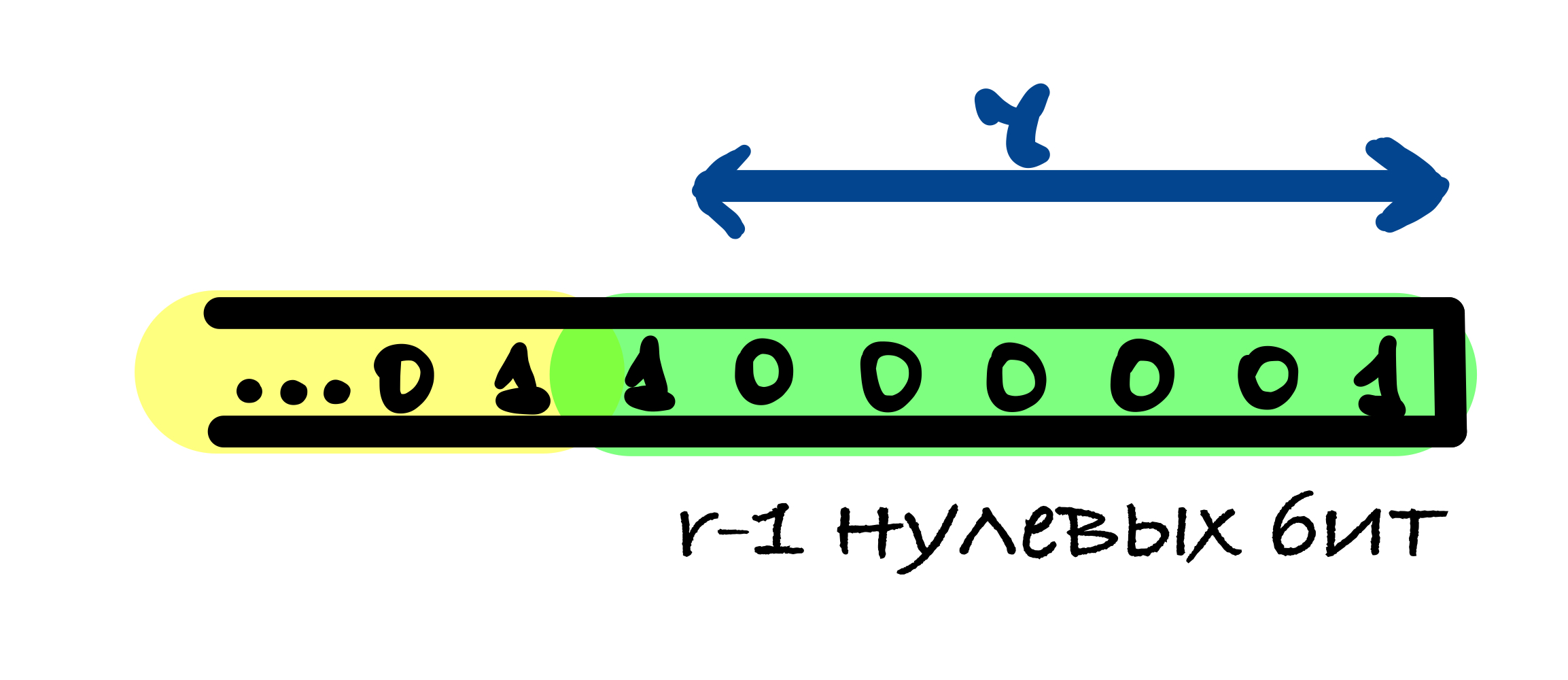
Если длина исходного сообщения M делится на r, то в этом случае к сообщению добавляется блок, начинающийся и оканчивающийся единицами, между которыми находятся r — 2 нулевых бит. Это делается для того, чтобы для сообщения, оканчивающегося последовательностью бит как в функции дополнения, и для сообщения без этих бит значения хеш-функции были различны.
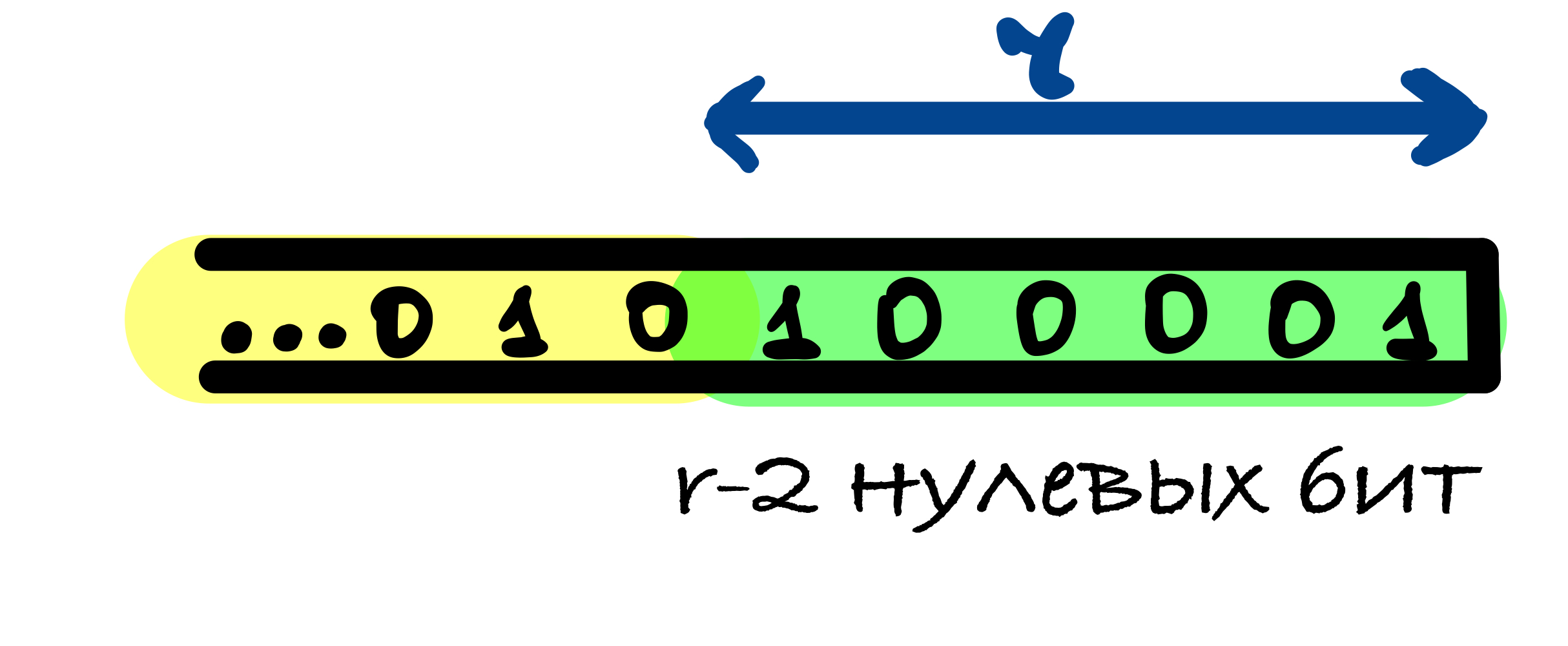
Первый единичный бит в функции дополнения нужен, чтобы результаты хеш-функции от сообщений, отличающихся несколькими нулевыми битами в конце, были различны.
Функция перестановок
Базовая функция перестановки состоит из раундов по пять шагов:
Тета, Ро, Пи, Хи, Йота
Далее будем использовать следующие обозначения:
Так как состояние имеет форму массива , то мы можем обозначить каждый бит состояния как
Обозначим результат преобразования состояния функцией перестановки
Также обозначим функцию, которая выполняет следующее соответствие:
— обычная функция трансляции, которая сопоставляет биту бит ,
где — длина слова (64 бит в нашем случае)
Я хочу вкратце описать каждый шаг функции перестановок, не вдаваясь в математические свойства каждого.
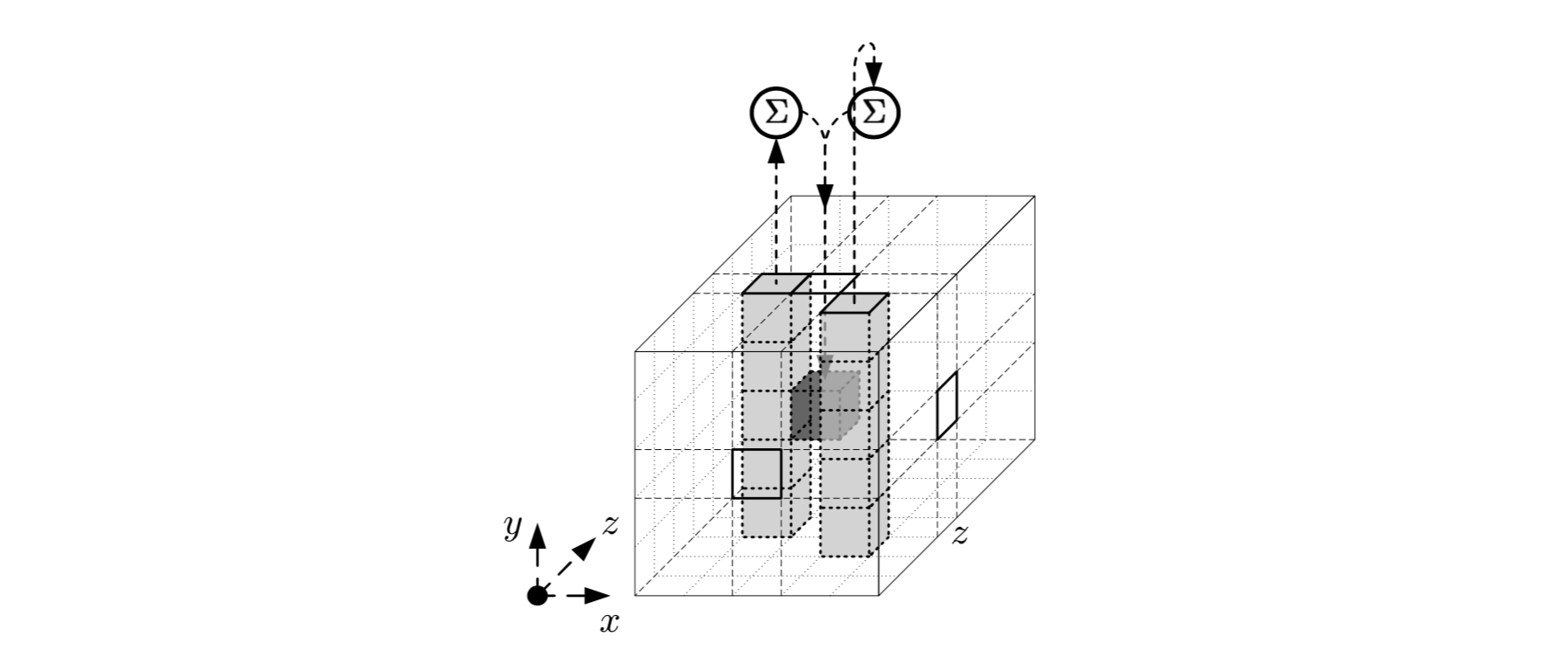
Шаг
Эффект отображения можно описать следующим образом: оно добавляет к каждому биту побитовую сумму двух столбцов и
Схематическое представление функции:

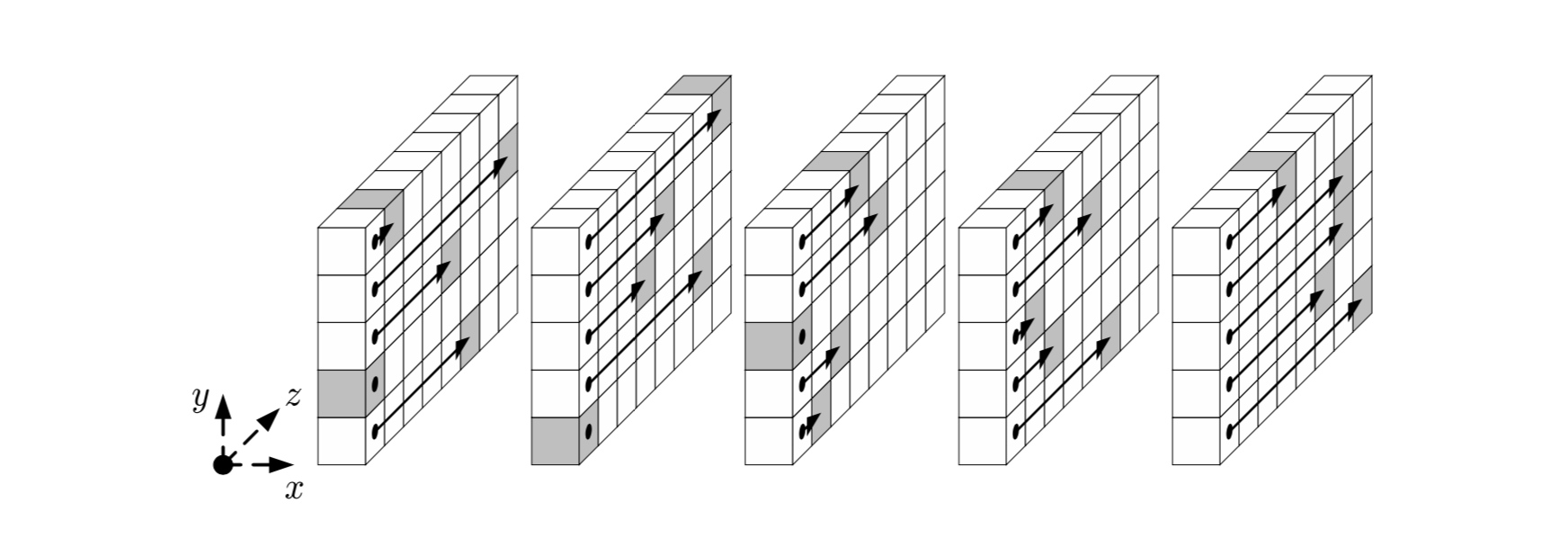
Шаг
Отображение направлено на трансляции внутри слов (вдоль оси z).
Проще всего его описать псевдокодом и схематическим рисунком:

Шаг
Шаг представляется псевдокодом и схематическим рисунком:


Шаг
Шаг является единственный нелинейным преобразованием в
Псевдокод и схематическое представление:

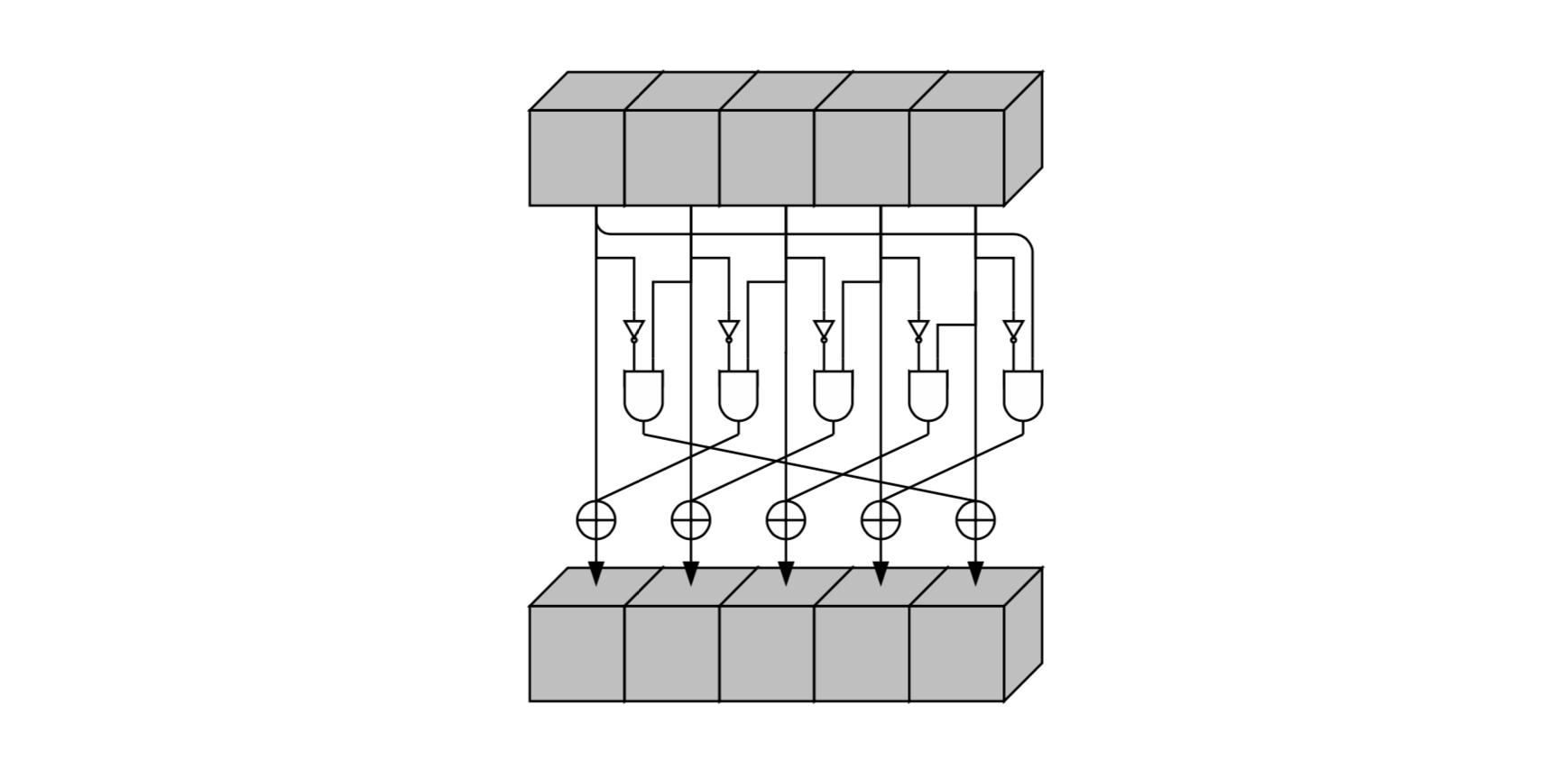
Шаг
Отображение состоит из сложения с раундовыми константами и направлено на нарушение симметрии. Без него все раунды были бы эквивалентными, что делало бы его подверженным атакам, использующим симметрию. По мере увеличения раундовые константы добавляют все больше и больше асимметрии.
Ниже приведена таблица раундовых констант для бит

Все шаги можно объединить вместе и тогда мы получим следующее:


Где константы являются циклическими сдвигами и задаются таблицей:
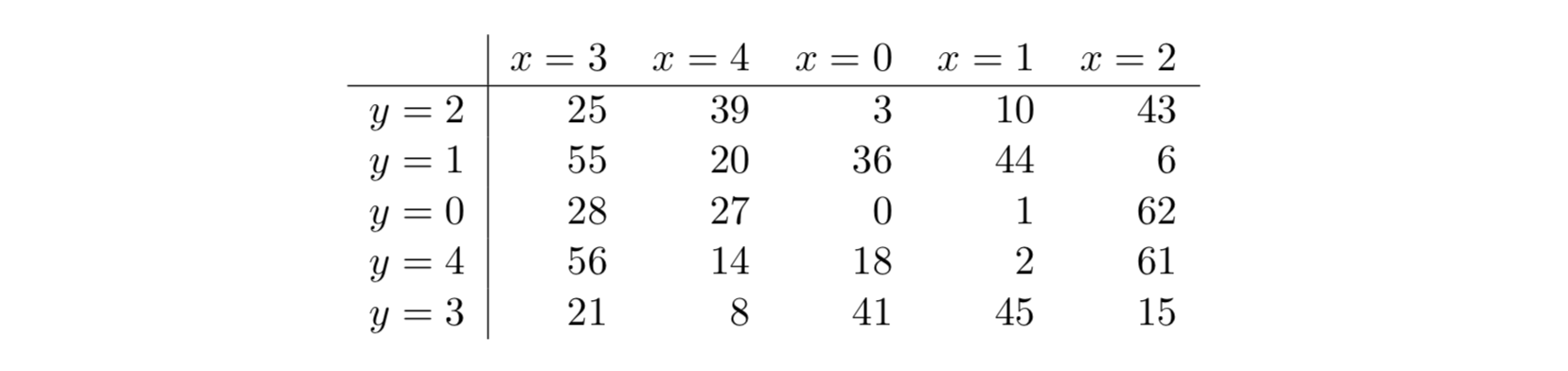
Итоги
В данной статье я постарался объяснить, что такое хеш-функция и зачем она нужна
Также в общих чертах мной был разобран принцип работы алгоритма SHA-3 Keccak, который является последним стандартизированным алгоритмом семейства Secure Hash Algorithm
https://ida-freewares.ru/chto-takoe-hash.html
https://habr.com/ru/post/534596/